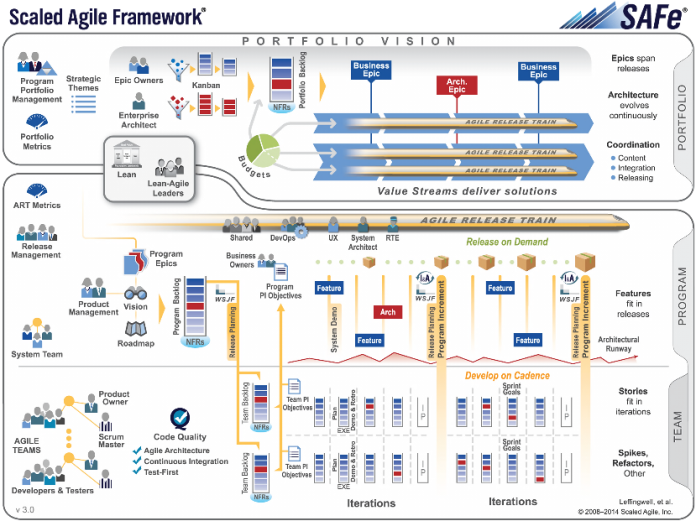
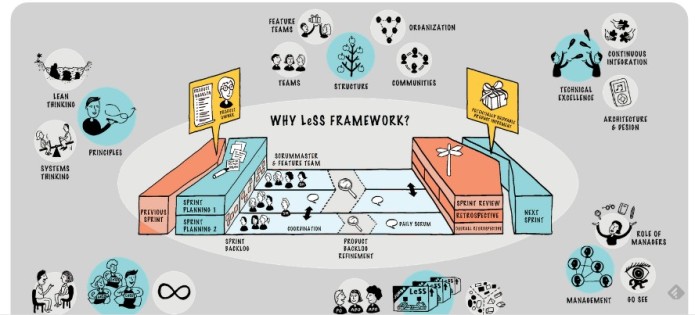
La relación entre Agile, los marcos de escalado y DevOps es una duda recurrente en los primeros pasos de los procesos de transformación.
Scaled Agile Framework (SAFe) (r) prescribe la entrega de código potencialmente implantable cada dos semanas, sincronizando así a todos los equipos en un programa. Además, también obliga a realizar una demo integrada al final del sprint. El comité de Release Management analiza si el incremento de funcionalidad es suficientemente valioso para el negocio y si los tiempos son los adecuados. En caso afirmativo pide a DevOps que se inicie el proceso de implantación de la versión entregada. Este segundo proceso, no está sincronizado con la entrega de versión desde desarrollo, y se realiza en función de las necesidades del negocio. Pero ¿cómo opera DevOps?
Esta parte, en la versión 3.0 de SAFe, no está totalmente especificada, pero utilizamos la forma de actuar del equipo de ingeniería de Rally como base para plantear una alternativa base para nuestros clientes.
Es un proceso a medio plazo y requiere un nivel de madurez elevado. Inicialmente no todo el mundo está preparado para que el proceso de puesta en producción este gobernado por la automatización, verificado por pruebas automatizadas y frameworks de monitorización de servidores de producción. Normalmente, estas fases del proceso de transformación se realizan al final del propio proceso.
Se trata de pasar del concepto de integración continua al deployment continuo. Aquí inicialmente es necesario distinguir código y servicios de infraestructura de servicios de presentación. Obviamente la automatización de los servicios de presentación requiere la intervención de gente de usabilidad, y por lo tanto es normalmente mucho más complicado automatizar dichas pruebas. De intentarse esto, es recomendable hacerlo al final y definir procesos de inspección humana antes del lanzamiento del pipeline de deployment.
Atacar la automatización del pipeline de deployment para servicios de infraestructura es sustancialmente más sencillo, y permite obtener experiencia y lecciones aprendidas más fácilmente. No todos los procesos de deployment son iguales y es necesario comenzar con algo manejable para entender y optimizar el proceso.
Se trata de identificar un equipo que normalmente entregue código de infraestructura (inicialmente suele ser el equipo de sistema) y comenzar a analizar todo el pipeline que tiene desde que la tarea es terminada en el IDE del desarrollador hasta que llega a estar disponible para el usuario final.
Identificaremos trabajo sin valor para proponer su eliminación, y trabajo automatizable para proceder progresivamente a su automatización. Al menos deben estar automatizadas las pruebas unitarias y las de integración, junto con las de regresión. Esto asume que el equipo usa TDD y entrega con el código pruebas funcionales suficientes para verificar la funcionalidad (como se hace el SAFe). Es altamente recomendable que se audite la cobertura de dichos sets de pruebas, y se establezcan límites razonables de cobertura comprobados previamente antes de la puesta en producción.
Además, se añade un paso adicional de pruebas que tiene más que ver con verificar el compliancy de los propios servidores de producción (puertos abiertos, configuraciones, etc…). Esto también se automatiza en el pipeline de deployment.
A partir de ahí, una vez que el comité de Release Management dé su aprobación, podemos llegar a poner en producción varias versiones al día como hace Rally.
DevOps es la manera de acortar los ciclos de feedback para entregar valor antes y reducir el coste del error. Sin esto, ¡el valor que generan los equipos ágiles puede estar atascado en Ops!

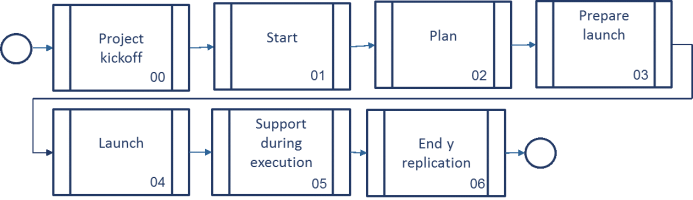
 Start
Start Plan
Plan Prepare Launch
Prepare Launch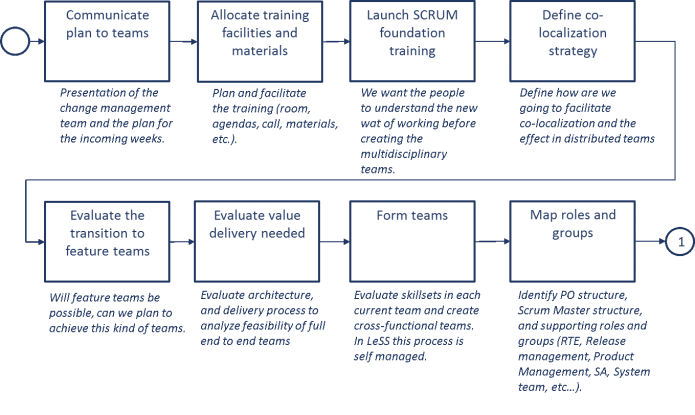
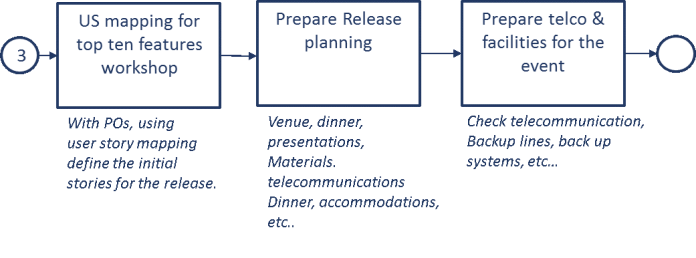 Launch
Launch Support during execution
Support during execution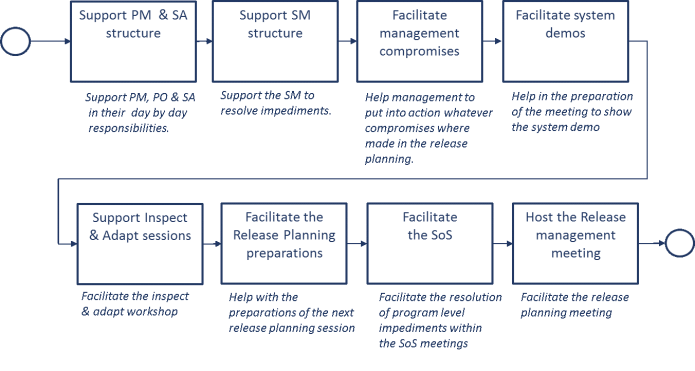 End & Replicate
End & Replicate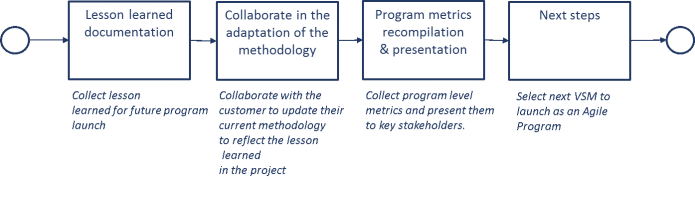
 Es la típica frase que se lee en toda la literatura sobre agilidad. Pero cómo definirlo. Es algo así como la confianza, y la autoridad derivadas de la naturaleza de las decisiones que el equipo puede tomar por sí mismo. Y el proceso de delegar en los equipos aquellas decisiones que, por su naturaleza, sean más eficientes tomarlas en el seno del propio equipo.
Es la típica frase que se lee en toda la literatura sobre agilidad. Pero cómo definirlo. Es algo así como la confianza, y la autoridad derivadas de la naturaleza de las decisiones que el equipo puede tomar por sí mismo. Y el proceso de delegar en los equipos aquellas decisiones que, por su naturaleza, sean más eficientes tomarlas en el seno del propio equipo.